Kodiak User's Guide
Introduction
This document is a "User's Guide" for the Kodiak high performance computing cluster. It is assumed that you familiar with the basics of using Linux and Unix-like systems and can connect to Kodiak using ssh, PuTTY, etc. If not, a Beginner's Guide, is also available. Although this document does discuss compiling and running programs on Kodiak, it is not meant to be a comprehensive tutorial. Hopefully, it will be enough to get you started.
You will need an account to use Kodiak. Kodiak accounts are available to Baylor faculty, graduate and undergraduate students. To request an account, contact Mike_Hutcheson@baylor.edu and/or Brian_Sitton@baylor.edu. Students should have their faculty sponsor request the account on the student's behalf. Accounts are also available to non-Baylor individuals who are collaborating with Baylor researchers.
Note: This document is a "work in progress". If anything is unclear, inaccurate, or even outright wrong please send email to Carl_Bell@baylor.edu.
Contents
- Overview
- Environment Modules
- Compiling Your Program
- Running Your Program
- Special Cases
- Debugging
- Transferring Files
Overview
Kodiak is a high performance compute cluster, consisting of many connected computers or nodes that work together so that they can be viewed as a single system. When you log in to Kodiak, you are actually logging into what is called the "login node", "head node", or "admin node". The login node is where you do your interactive work such as editing files, compiling your programs, etc. There are also many compute nodes which do the actual work.
The compute nodes are named "n001", "n002", etc. The login node is actually "login001" in addition to "kodiak".
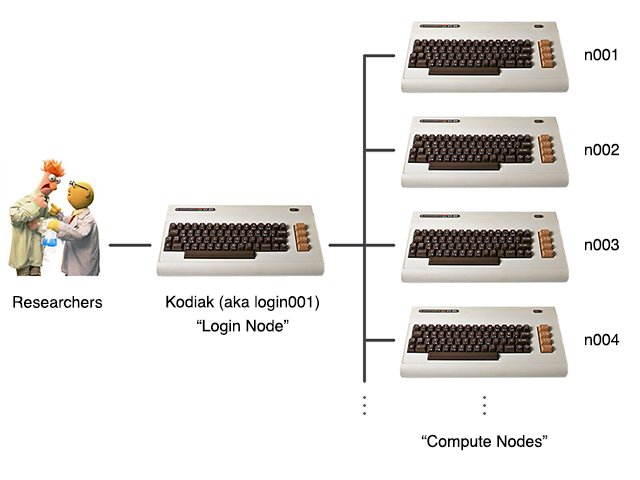
Note: Kodiak's regular compute nodes are dual-socket 18-core systems. So each node has a total of 36 cores or processors and can run 36 programs simultaneously. There are other types of compute nodes as well, including NVIDIA GPU systems, Intel Phi, and HP "moonshot" systems.
Note: These days, the terms "CPU", "processor", and "core" are often used interchangeably. As you'll see below, you will often need to specify "processors per node", so we will usually use the term "processor" throughout the rest of this document.
Although there are several different file systems on Kodiak, the two that you are most likely to work with directly are /home and /data. The /home file system is the default location for Kodiak users' home directories. Your source code, compiled programs, documentation, etc., should be stored here. If your username were bobby, your home directory would be "/home/bobby". Two common abbreviations for your home directory are "~" and the environment variable "$HOME". The /data file system, which is much larger than /home, is where you should store your research data. Like your home directory, your "data directory" is "/data/bobby". Both file systems are accessible from both the login node and compute nodes.
Environment Modules
Before we continue, we need to discuss Environment Modules (sometimes just called "Modules").
There may be multiple versions of some software packages installed on Kodiak. For example, there are currently three different versions of the GNU compiler suite (gcc) available: 4.8.5, 5.4.0, and 6.3. So how do you choose which one to use? In the Kodiak Beginner's Guide, it was mentioned that the $PATH environment variable is used to find the specific program to run when you enter its name on the command line. Because the directory (/usr/bin) that contains the system's default gcc executable is included in your session's default $PATH environment variable, when you run gcc the system will just use that version. But what if you want to use one of the other versions of gcc? You could modify $PATH in your .bash_profile or .bashrc startup scripts but that's an all or nothing setting so what if you want to use different versions of gcc depending on what you need to compile? What if the location of gcc changes? Are there any environment variables other than $PATH need to be set to use a different version of gcc? (Yes there are.)
This is where Environment Modules help. These are "modules" that you can load (and unload) in your session that dynamically set the environment variables needed to run specific programs. So if you want to use version 6.3 of gcc instead of 4.8.5 (Kodiak's default version) you would load the gcc 6.3 module and from then on (during that session) running gcc would run gcc 6.3.
This is done with the module command. To see what modules are available, run module avail.
$ module avail
------------------------ /usr/local/Modules/modulefiles ------------------------
ec2-cli/1.7.5.1 mesa/6794
fftw3-gcc/3.3.5-mvapich2 mvapich2-gcc/2.2-2(default)
fftw3-gcc/3.3.5-openmpi mvapich2-gcc/2.2-3b
fftw3-intel/3.3.5-mvapich2 mvapich2-intel/2.2-2(default)
fftw3-intel/3.3.5-openmpi mvapich2-intel/2.2-2-18.2
gcc/5.4.0 openmpi-gcc/2.0.1
gcc/6.3.0 openmpi-intel/1.10.3
geant4/10.1.1 openmpi-intel/2.0.1
gerris/131206 python/2.7.10(default)
gfsview/121130 python/2.7.14
gromacs/2016.1 python/3.6.6
gromacs/jnk python/3.7.0
hdf5/5-1.10 R/3.3.2
intel/17.01(default) R/3.5.1
intel/18.2 us3d/build1
intelmpi/18.2.199 us3d/build1-bss
jags/4.0.0 us3d/build2
julia/0.4.6 use.own
matlab/2016a(default) visit/2.12.1
matlab/2017a
Note: In addition to the modulefiles located in /usr/local/Modules/modulefiles there are many modulefiles in /cm/local and /cm/shared. Because most users won't ever use them, this document will usually omit them from output to simplify things a bit.
You can see modules for the different versions of gcc in the list. There isn't a module for gcc 4.8.5 because that is a system default so a module is not needed.
Now let's switch to a different version of gcc. We can see which version that we are currently set to use with which gcc and/or the gcc --version command. To see which modules are loaded, use the module list command. Now, to load a module, use the module load .
$which gcc/usr/bin/gcc $gcc --versiongcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-16) Copyright (C) 2015 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. $module listNo Modulefiles Currently Loaded. $module load gcc/6.3.0$module listCurrently Loaded Modulefiles: 1) gcc/6.3.0 $which gcc/usr/local/gcc/6.3.0/bin/gcc $gcc --versiongcc (GCC) 6.3.0 Copyright (C) 2016 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
To stop using this version of gcc you will need to unload/remove the module with the module unload command. ("rm" is a synonym for "unload" so you could also run module rm .) It is possible to have multiple modules loaded, so if you want to unload all of them at the same time, run module purge.
$module listCurrently Loaded Modulefiles: 1) gcc/6.3.0 $module unload gcc$module listNo Modulefiles Currently Loaded. $module load gcc/6.3.0$module load R/3.3.2$module load matlab/2017a$module listCurrently Loaded Modulefiles: 1) gcc/6.3.0 2) intel/17.01 3) R/3.3.2 4) matlab/2017a $module purge$module listNo Modulefiles Currently Loaded.
The module command is pretty clever and can sometimes figure out the version for you so you may not always have to specify the full version in a command. (Doesn't hurt, though.) Also, some modules, such as matlab above, even have default versions so that will get used if you don't specify the version.
Did you happen to notice above that "intel/17.01" was included in the list of loaded modules even though we didn't add it? It just so happens that the intel module is required by R so the intel/17.01 module was implicitly loaded by the R module.
Any currently loaded modules will not be loaded if you log out and log back in. If you know that you will always want use gcc 6.3.0, you could add module load gcc/6.3.0 to your .bashrc or .bash_profile startup script and you won't have to run it every time you log in.
[Advanced] Creating Your Own Modules
It's also possible for you to create your own custom modulefiles. Why would you want to do this? You may be using software that instructs you to modify the $PATH or $LD_LIBRAY_PATH environment variables in your .bashrc startup script. Or perhaps you want to build and install a custom version of python in your home directory (talk to us before you do that...) and use it instead of one of the installed versions.
To use your own custom modulefiles, you need to load the standard "use.own" module. This will add the directory ~/privatemodules to the list of directories where the module command looks for modulefiles. The directory will be automatically created the first time you load use.own. Although not required, to reinforce the fact that these modulefiles are your own, and to avoid potential naming conflicts with modulefiles on the system, you should create a directory named "my" within the privatemodules directory.
$module load use.own$cd ~/privatemodules$mkdir my$cd my
Compiling Your Program
Compiling
Most programs need to be compiled (and linked) before they can be run. Shell scripts and other interpreted languages are an exception. There are two sets of compilers on Kodiak - Intel and GNU. To compile a simple program, the command is usually something like:
compiler -o output_file source_file(s)
The -o option specifies the name of the output file (i.e., the executable program) to create. If you omit this option, the executable program will likely be called "a.out". Be very careful to avoid accidentally using the name of a source file as the output file because the compiler may overwrite your source file without warning.
Note: More complex programs will likely include libraries and require other compiler options. Programs are often compiled or built with the make command and "makefiles". To keep things simple, this document will use trivial, single source file, programs.
Below are four versions (C, C++, Fortran 77, and Fortran 90) of a trivial "hello world" program that prints out a simple greeting along with the name of the host the program is running on.
$pwd/home/bobby/howdy $lshowdy.c howdy.cc howdy.f howdy.f90 $cat howdy.c#include int main() { char hostname[80]; gethostname(hostname, 80); printf("Node %s says, "Howdy!"\n", hostname); } $cat howdy.cc#include #include int main() { char hostname[80]; gethostname(hostname, 80); std::cout << "Node " << hostname << " says, "Howdy!"" << std::endl; } $cat howdy.fPROGRAM HOWDY INTEGER STATUS CHARACTER*(80) HOST STATUS = HOSTNM(HOST) PRINT *, 'Node ',TRIM(HOST),' says, "Howdy!"' END PROGRAM HOWDY $cat howdy.f90program howdy character*(80) :: host integer :: status status = hostnm(host) print *, 'Node ', trim(host), ' says, "Howdy!"' end program howdy
To compile the above programs with the GNU compilers, use the gcc command for C, the g++ command for C++, and the gfortran command for Fortran 77 and Fortran 90/95. You may see references to the cc C compiler. On Kodiak, the cc compiler is actually a symbolic link to gcc. Similarly, documentation for some Fortran programs may say to use the g77 compiler. The g77 compiler has been replaced by gfortran.
$gcc -o howdy howdy.c$g++ -o howdy howdy.cc$gfortran -o howdy howdy.f$gfortran -o howdy howdy.f90
To compile the above programs with the Intel compilers, use the icc command for C, the icpc command for C++, and the ifort command for Fortran 77 and Fortan 90/95.
$icc -o howdy howdy.c$icpc -o howdy howdy.cc$ifort -o howdy howdy.f$ifort -o howdy howdy.f90
$ ./howdy
Node login001 says, "Howdy!"
When we run the "howdy" program on the login node, we can see that the hostname is "login001" as expected. Remember that you will normally run your program on one or more compute nodes and not the login node. We'll discuss how below.
MPI
Note: This document is not a tutorial on parallel/MPI programming. Instead, it is assumed that you are already familiar with MPI programming or have MPI based software developed by a third party and are looking for information on building and running your MPI program on Kodiak.
On Kodiak, there are multiple implementations of MPI ("Message Passing Interface"), a common protocol/API used to write parallel programs. In the past, you had to use the mpi-selector command to specify which implementation of MPI to use with. This is no longer supported. You must use the module load command instead.
$module listNo Modulefiles Currently Loaded. $module avail------------------------ /usr/local/Modules/modulefiles ------------------------ ec2-cli/1.7.5.1 matlab/2016a(default) fftw3-gcc/3.3.5-mvapich2 matlab/2017a fftw3-gcc/3.3.5-openmpi mesa/6794 fftw3-intel/3.3.5-mvapich2 mvapich2-gcc/2.2-2(default) fftw3-intel/3.3.5-openmpi mvapich2-gcc/2.2-3b gcc/5.4.0 mvapich2-intel/2.2-2(default) gcc/6.3.0 mvapich2-intel/2.2-2-18.2 geant4/10.1.1 openmpi-gcc/2.0.1 gerris/131206 openmpi-intel/1.10.3 gfsview/121130 openmpi-intel/2.0.1 gromacs/2016.1 python/2.7.10(default) gromacs/jnk python/2.7.14 hdf5/5-1.10 R/3.3.2 intel/17.01(default) us3d/build1 intel/18.2 us3d/build1-bss intelmpi/18.2.199 us3d/build2 jags/4.0.0 use.own julia/0.4.6 visit/2.12.1 $module load mvapich2/1.9-gcc-4.9.2$module listCurrently Loaded Modulefiles: 1) gcc/4.9.2 2) mvapich2/1.9-gcc-4.9.2
Below are two versions (C and Fortran) of our "howdy" program modified to use MPI to run in parallel on multiple processors/nodes. In addition to printing out the hostname, each process also prints out the MPI "rank" and "size". Basically, the size is the total number of processes of the MPI job and the rank is the unique id of an individual process.
$cat howdies.c#include #include int main(int argc, char **argv) { int rank, size; char hostname[80]; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); gethostname(hostname, 80); printf("Howdy! This is rank %d of %d running on %s.\n", rank, size, hostname); MPI_Finalize(); return 0; } $cat howdies.f90program howdies ! The "use ifport" is needed if compiling with the Intel compiler. ! use ifport implicit none include "mpif.h" integer(kind=4) :: ierr integer(kind=4) :: myid, numprocs character*(MPI_MAX_PROCESSOR_NAME) :: host integer :: resultlen call MPI_INIT(ierr) call MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD, numprocs, ierr) call MPI_GET_PROCESSOR_NAME(host, resultlen, ierr) print *, 'Howdy! This is rank ', myid, ' of ', numprocs, 'running on ', host(1:resultlen) call MPI_FINALIZE(ierr) end program howdies
Compiling an MPI program, even trivial programs like the ones above, is a bit complex. There are various compiler options, library and include directories, libraries, etc., that need to be specified. Fortunately, the MPI implementations do all of this for you with special "wrapper" compiler commands. To compile an MPI program written in C, use the mpicc command. To compile an MPI program written in Fortran, use either the mpif77 or mpif90. Some implementations of MPI may have an mpifort command that can compile both Fortran 77 or Fortran 90/95 programs.
Note: The default compiler that will be used to compile your MPI program (i.e., implicitly used by mpicc/mpif90) will be the one that was used to compile that implementation of MPI. When you load the MPI module, if necessary, the compiler's module should automatically get loaded as well. If you want to be sure, you can run mpicc --version or mpif90 --version and you should see the compiler and version that will be used to compile your MPI program.
$mpicc -o howdies howdies.c$mpif90 -o howdies howdies.f90
Running Your Program
The Batch System
As has been mentioned above, you typically edit and compile your programs on the login node, but you actually run the programs on the compute nodes. But there are many compute nodes, possibly running other programs already. So how do you choose which compute node or nodes to run your program on?
You don't, at least, not explicitly. Instead you use Kodiak's batch system. You tell the batch system the resources, such as how many nodes and processors, that your program requires. The batch system knows what is currently running on all of the compute nodes and will assign unused nodes to your program if they are available and automatically run your program on them. If none are available, your program will wait in a queue until they are. When dealing with the batch system, you will occasionally see the abbreviation "PBS" which stands for "Portable Batch System".
Submitting Jobs
We'll use the example C program, "howdy.c", from above. When we run it on the login node, we can see that the hostname is "login001" as expected. Again, you will not run your program on the login node. This is just an example.
$pwd/home/bobby/howdy $lshowdy.c $cat howdy.c#include int main() { char hostname[80]; gethostname(hostname, 80); printf("Node %s says, "Howdy!"\n", hostname); } $gcc -o howdy howdy.c$./howdyNode login001 says, "Howdy!"
To run your program on Kodiak, you need to submit it to the batch system. This is done with the qsub command and is known as submitting a job. If you try to submit the executable program itself, you will get an error message. Instead, you submit a shell script that runs your program. The shell script can be extremely basic, possibly a single line that runs the program. Or it can be complex, performing multiple tasks in addition to running your program.
$qsub ./howdyqsub: file must be an ascii script $lshowdy howdy.c howdy.sh $cat howdy.sh/home/bobby/howdy/howdy $qsub howdy.sh1628740.n131.localdomain
Notice that the qsub command above returned the text "1628740.n131.localdomain". This is known as the job id. You will usually only care about the numeric part.
Getting Job Info
When you submit a job on Kodiak, it is placed in a queue. If your job's requested resources (nodes and processors) are available, then the job is run on a compute node right away. Because Kodiak runs jobs for many users, it is possible that all of the processors on all of the nodes are currently in use by others. When that happens, your job will wait until the requested resources are free and wait in a queue. The queue is, for the most part, "first come, first served". If two jobs are waiting and both require the same resources, then the job that was submitted earlier will run first.
You can get a list of all of the jobs currently running or waiting to run with the qstat command.
$ qstat
Job id Name User Time Use S Queue
------------------------- ---------------- --------------- -------- - -----
1628716.n131 prog_01a betty 1414:57: R batch
1628717.n131 prog_01b betty 1414:57: R batch
1628718.n131 prog_02a betty 1228:40: R batch
1628719.n131 prog_02b betty 1228:40: R batch
1628720.n131 prog_03a betty 0 Q batch
1628721.n131 prog_03b betty 0 Q batch
1628731.n131 qcd bubba 00:12:13 R batch
1628740.n131 howdy.sh bobby 0 R batch
You can see each job's job id, name, user, time used, job state, and queue. (There are actually multiple queues on Kodiak. The default queue is named "batch" and is the one you will usually use.) The "S" column shows the job's current state. An "R" means the job is running; "Q" means it is queued and waiting to run. Other state values that you may see are E (exiting), C (complete), and H (held).
You can display just your jobs by adding a -u option. You can also display the nodes that a job is using with the -n option. You can see below that your job is running on node n124.
$ qstat -n -u bobby
n131.localdomain:
Req'd Req'd Elap
Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time
-------------------- ----------- -------- ---------------- ------ ----- ------ ------ ----- - -----
1628740.n131.loc bobby batch howdy.sh 22787 1 1 -- 5000: R --
n124/0
If, for some reason, you want to stop your job, you can do so with the qdel command. If your job is currently running, qdel will terminate it on the compute node(s). Otherwise it will simply remove it from the queue. Specify the job's job id without the ".n131.localdomain" bit. You can only qdel your own jobs.
$ qdel 1628740
Job Output
The "howdy" program normally prints it output on the terminal, i.e., standard output. But when you submit your job it runs on some compute node that doesn't have a terminal. So where does the output go? By default, standard output is saved to a file named ".o". So in our job above, the output file is "howdy.sh.o1628740". There is a similar file, "howdy.sh.e1628740" for standard error output as well. (Hopefully, the error file will be empty...) Note that these files will contain stdout and stderr only. If your program explicitly creates and writes to other data files, that output will not appear in the job's output file.
$lshowdy howdy.c howdy.sh howdy.sh.e1628740 howdy.sh.o1628740 $cat howdy.sh.o1628740Node n124 says, "Howdy!"
The output and error files are created once your program begins running on the compute node(s) and stdout and stderr are appended to the files. If your job takes a long time to complete but periodically writes to stdout, a very useful command is tail -f which allows you to continuously watch your file as your job appends output to it. This way you can see if the job is performing as expected. Something to keep in mind if your job runs on multiple/parallel processes is that the stdout from each process is appended to your job's output file. The order of the output is undefined so your output file may be jumbled.
More On Submitting Jobs
Above, we submitted a minimal shell script with qsub. By default, qsub will allocate one processor on one node to the job. If you are submitting a parallel/MPI program, you would need to specify more than that. Below is the parallel version of the "howdy" program, called "howdies", compiled with mpicc. In addition to printing out the hostname, it prints out the MPI "rank" and "size".
$cat howdy.c#include #include int main(int argc, char **argv) { int rank, size; char hostname[80]; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); gethostname(hostname, 80); printf("Howdy! This is rank %d of %d running on %s.\n", rank, size, hostname); MPI_Finalize(); return 0; } $mpicc -o howdies howdies.c
To run an MPI program, you can't just run the program. Instead you use the mpiexec command with your program as one of its arguments and it will launch multiple instances of your program for you. You specify how many processes to launch with the -n option and on which nodes to launch them (with the -machinefile option). The "machine file" is just a text file containing a list of nodes to run on.
Note: In the past, you would use the mpirun to run an MPI program. Although some programs' documentation may still say to use mpirun, don't. Use mpiexec instead.
$mpiexec -n 16 -machinefile some_nodes.dat /home/bobby/howdy/howdies$cat some_nodes.datn001 n001 n001 n001 n001 n001 n001 n001 n002 n002 n002 n002 n002 n002 n002 n002
So we need to put the above line in a shell script and to submit with qsub. But what about the machine file? How do we know what nodes to place in there? We don't. Remember that the batch system allocates the nodes and creates the machine file for us. But it will also put the path to that machine file in an environment variable, $PBS_NODEFILE, that our submitted script can use. Below is a quick test script that just displays $PBS_NODEFILE and its contents. Note that the created machine file (and the $PBS_NODEFILE environment variable) only exists during the execution of a submitted job on a compute node so we'll need to qsub it and look at the results in the job's output file.
$cat test.shecho $PBS_NODEFILE echo cat $PBS_NODEFILE $qsub test.sh1748929.n131.localdomain $cat test.sh.o1748929/var/spool/torque/aux//1748929.n131.localdomain n126 n126 n126 n126 n126 n126 n126 n126 n103 n103 n103 n103 n103 n103 n103 n103
We see that there are 16 lines in the machine file, eight n126s and eight n103s. So when we call mpiexec with an option -n 16, eight processes will launch on n126 and eight will launch on n103. Recall that earlier we stated that the default behavior of the batch system is to allocate one processor on one node. So how did the batch system know to put 16 entries in the file instead of just 1 entry? Because this document cheated. The qsub command above would not actually create the machine file that was displayed. We also need to tell qsub how many processors we plan to use with the -l nodes=N:ppn=P option. (That's a lower case L and not a one, and stands for "resource_list".)
With the -l option, you are actually requesting the number of processors per node. MPI programs typically run one process per processor so it is often convenient to think of "ppn" as "processes per node" instead of "processors per node". But that's not entirely accurate, and not always the case, even with MPI programs.
The -l option to create the above machine files was actually:
qsub -l nodes=2:ppn=8
which is 2 nodes x 8 processors per node = 16 total processors. If your program is memory intensive, you might need to run fewer processes per nodes, so instead you could use:
qsub -l nodes=4:ppn=4
mpiexec -n 16 ...
which is 4 nodes x 4 processors per node = 16 total processors. You also aren't required to have the same number of processes running on every node. If your program requires 20 processes, you would use:
qsub -l nodes=2:ppn=8+1:ppn=4
mpiexec -n 20 ...
which means 2 nodes x 8 processors per node + 1 node x 4 processors per node = 16 + 4 = 20 total processors. The -l option is also used to request resources in addition to node/processes. For example, you can request specific nodes or specify a maximum cpu time or wall time that your program should use.
Note: Above we said "if your program is memory intensive". So what would be considered "memory intensive"? Each compute node has 16 GB of memory, which is 2 GB per process. Most programs don't require that much so don't specify fewer processors per node unless you know for certain that there is insufficient memory.
When your job is running, you can ssh to a compute node and run the top command. One of columns is "%MEM" which shows a task's currently used share of available physical memory. If the sum of the percentages is close to (or greater than) 100%, consider decreasing the number of processes per node.
So now back to our "howdies" program. Let's say we want to run it with 8 processes, but only 4 per node. By the way, when the job runs, its current working directory will be your home directory and not the directory that you submitted it. We'll use the $PBS_O_WORKDIR environment variable to cd to it rather than hard-code paths in the script.
We also need to specify which version of MPI to use when running our program. To do this, add a module load command at the top of the script. This should be the same module that was used to compile the program. It is probably a good idea to module purge any other loaded modules just to make sure there are no conflicts.
$cat howdies.sh#!/bin/sh module purge module load mvapich2/1.9-gcc-4.9.2 echo "Job working directory: $PBS_O_WORKDIR" echo cd $PBS_O_WORKDIR mpiexec -n 8 -machinefile $PBS_NODEFILE ./howdies $qsub -l nodes=2:ppn=4 howdies.sh1748932.n131.localdomain $lshowdies howdies.c howdies.sh howdies.sh.e1748932 howdies.sh.o1748932 howdy howdy.c howdy.sh test.sh $cat howdies.sh.o1748932Job working directory: /home/bobby/howdy Howdy! This is rank 5 of 8 running on n103 Howdy! This is rank 1 of 8 running on n126 Howdy! This is rank 2 of 8 running on n126 Howdy! This is rank 3 of 8 running on n126 Howdy! This is rank 0 of 8 running on n126 Howdy! This is rank 7 of 8 running on n103 Howdy! This is rank 6 of 8 running on n103 Howdy! This is rank 4 of 8 running on n103
Now let's run it but with only 4 processes (i.e., qsub -l nodes=1:ppn=4). But we need to remember to modify the script and change the mpiexec -n option. It would be useful if we could somehow calculate the total number of processes from the value(s) in qsub's -l option. Remember that the machine file ($PBS_NODEFILE) lists nodes, 1 per processor. The total number of processes is just the number of lines in that file. We can use the following:
cat $PBS_NODEFILE | wc -l
to return the number of lines. By placing that code within "backticks" (the ` character) we can assign the result of it to a variable in our shell script and use that with mpiexec.
Another useful thing is to use the uniq or sort -u commands with the $PBS_NODEFILE. This will print out non-repeated lines from the file, essentially giving you a list of the nodes your job is running on.
$cat howdies.sh#!/bin/sh module purge module load mvapich2/1.9-gcc-4.9.2 echo "Job working directory: $PBS_O_WORKDIR" echo num=`cat $PBS_NODEFILE | wc -l` echo "Total processes: $num" echo "Node(s):" uniq $PBS_NODEFILE echo cd $PBS_O_WORKDIR mpiexec -n $num -machinefile $PBS_NODEFILE ./howdies $qsub nodes=2:ppn=4 howdies.sh1748942.n131.localdomain $cat howdies.sh.o1748942Job working directory: /home/bobby/howdy Total processes: 8 Node(s): n084 n082 Howdy! This is rank 1 of 8 running on n084 Howdy! This is rank 2 of 8 running on n084 Howdy! This is rank 4 of 8 running on n082 Howdy! This is rank 0 of 8 running on n084 Howdy! This is rank 3 of 8 running on n084 Howdy! This is rank 6 of 8 running on n082 Howdy! This is rank 5 of 8 running on n082 Howdy! This is rank 7 of 8 running on n082
You can have the batch system send you an email when the job begins, ends and/or aborts with the -m and -M options:
-m bea -M Bobby_Baylor@baylor.edu
With the qsub -N option, you can specify a job name other than the name of the submitted shell script. The job name is shown in the output listing of the qstat command and is also used for the first part of the output and error file names.
If you are submitting jobs often, you may find yourself overwhelmed by the number of output files (jobname.o#####) and error files (jobname.e#####) in your directory. Some useful qsub options are -o and -e which allow you to specify the job's output and error file names explicitly rather than using the job name and job id. Subsequent job submissions will append to these files.
$qsub -l nodes=1:ppn=2 -o howdies.out -e howdies.err howdies.sh1748946.n131.localdomain $lshowdies howdies.c howdies.err howdies.out howdies.sh howdy howdy.c howdy.sh test.sh $cat howdies.outJob working directory: /home/bobby/howdy Total processes: 2 Node(s): n119 Howdy! This is rank 0 of 2 running on n119 Howdy! This is rank 1 of 2 running on n119
If your qsub options don't change between job submissions, you don't have to type them every time you run qsub. Instead, you can add PBS directives to your shell script. These are special comment lines that appear immediately after the "#!" shebang line. Each directive lines start with "#PBS" followed by a qsub option and any arguments.
$cat howdies.sh#!/bin/sh #PBS -l nodes=1:ppn=4 #PBS -o howdies.out #PBS -e howdies.err #PBS -N howdies #PBS -m be -M Bobby_Baylor@baylor.edu module purge module load mvapich2/1.9-gcc-4.9.2 echo "------------------" echo echo "Job working directory: $PBS_O_WORKDIR" echo num=`cat $PBS_NODEFILE | wc -l` echo "Total processes: $num" echo echo "Job starting at `date`" echo cd $PBS_O_WORKDIR mpiexec -n $num -machinefile $PBS_NODEFILE ./howdies echo echo "Job finished at `date`" $qsub howdies.sh1748952.n131.localdomain $cat howdies.outJob working directory: /home/bobby/howdy Total processes: 2 Howdy! This is rank 0 of 2 running on n119 Howdy! This is rank 1 of 2 running on n119 ------------------ Job working directory: /home/bobby/howdy Total processes: 4 Nodes: Job starting at Fri Dec 6 12:23:49 CST 2013 Howdy! This is rank 0 of 4 running on n075 Howdy! This is rank 1 of 4 running on n075 Howdy! This is rank 2 of 4 running on n075 Howdy! This is rank 3 of 4 running on n075 Job finished at Fri Dec 6 12:23:51 CST 2013
The batch system's queue is more or less FIFO, "first in, first out", so it's possible that your job may be waiting behind another user's queued job. But if the other user's job is requesting multiple nodes/processors, some nodes will remain unused and idle while waiting on other nodes to free up so that the job can run. The batch system tries to be clever and if it knows that your job can run and finish before then, rather than force your job to wait, it will allocate an idle node it and let it run. The default time limit for jobs is 5000 hours which is considered "infinite" by the batch system. You can specify a much shorter time for your job by adding a "walltime=hh:mm:ss" limit to the qsub command's -l option.
qsub -l nodes=1:ppn=1,walltime=00:30:00 howdy.sh
The job will may not run immediately, but after a set amount of time, should run before the other user's "big" job runs. Be aware that the walltime specified is a hard limit. If your job actually runs longer than the specified walltime, it will be terminated.
In the "Getting Job Info" section above, we saw that you can see the nodes that a job is running on by adding a -n option to qstat. If you added the uniq $PBS_NODEFILE command to your shells script, the nodes will be listed at the top of the job's output file. If necessary, you could log in to those nodes with ssh, and run top or ps to see the status of the processes running on the node. You could use ssh to run ps on the node without actually logging in.
[bobby@login001 howdy]$qsub howdies.sh1754935.n131.localdomain [bobby@login001 howdy]$qstat -u bobby -nn131.localdomain: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time -------------------- ----------- -------- ---------------- ------ ----- ------ ------ ----- - ----- 1754935.n131.loc bobby batch howdies 23006 1 1 -- 5000: R -- n010/0 [bobby@n130 howdy]$ssh n010[bobby@n010 ~]$ps u -u bobbyUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND bobby 23006 0.0 0.0 65924 1336 ? Ss 10:52 0:00 -bash bobby 23065 0.0 0.0 64348 1152 ? S 10:52 0:00 /bin/bash /var/spool/torque/... bobby 23072 0.2 0.0 82484 3368 ? S 10:52 0:00 mpiexec -n 1 -machinefile /var/spool/torque/aux//1754935.n131.local bobby 23073 0.3 0.0 153784 7260 ? SLl 10:52 0:00 ./howdies bobby 23078 0.0 0.0 86896 1708 ? S 10:52 0:00 sshd: bobby@pts/1 bobby 23079 0.2 0.0 66196 1612 pts/1 Ss 10:52 0:00 -bash bobby 23139 0.0 0.0 65592 976 pts/1 R+ 10:52 0:00 ps u -u bobby [bobby@n010 ~]$exit[bobby@n130 howdy]$ [bobby@n130 howdy]$ssh n010 ps u -u bobbyUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND bobby 23006 0.0 0.0 65924 1336 ? Ss 10:52 0:00 -bash bobby 23065 0.0 0.0 64348 1152 ? S 10:52 0:00 /bin/bash /var/spool/torque/... bobby 23072 0.0 0.0 82484 3368 ? S 10:52 0:00 mpiexec -n 1 -machinefile /var/spool/torque/aux//1754935.n131.localdomain ./howdies bobby 23073 0.1 0.0 153784 7260 ? SLl 10:52 0:00 ./howdies bobby 23146 0.0 0.0 86896 1672 ? S 10:53 0:00 sshd: bobby@notty bobby 23147 2.0 0.0 65592 972 ? Rs 10:53 0:00 ps u -u bobby
This was easy for a trivial, one-process job. If your job is running on several nodes, it can be a hassle. A useful trick is to add following function to your .bashrc startup script:
function myjobs()
{
if [ -f "$1" ]
then
for i in `cat "$1"`
do
echo "-----"
echo "Node $i:"
echo
ssh $i ps u -u $LOGNAME
done
fi
}
You could also modify the code above to be a standalone shell script if you wanted. Now within your shell script that you submit with qsub, add the following code:
# Parse the Job Id (12345.n131.localhost) to just get the number part
jobid_num=${PBS_JOBID%%.*}
nodelist=$PBS_O_WORKDIR/nodes.$jobid_num
sort -u $PBS_NODEFILE > $nodelist
What the above code does is parse the job id (environment variable $PBS_JOBID) to strip off the ".n131.localhost" part and then create a file, "nodes.12345", that contains a list of nodes that the job is running on. Once the job has completed, the nodes.12345 file is no longer useful. You could rm $nodelist at the bottom of the shell script if you wanted.
$qsub howdies.sh1754949.n131.localdomain $ls nodes*nodes.1754949 $myjobs nodes.1754949----- Node n022: USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND bobby 26684 0.0 0.0 73080 3108 ? Ss 14:01 0:00 orted -mca ess tm... bobby 26685 0.2 0.0 221420 7992 ? SLl 14:01 0:00 ./howdies bobby 26686 0.2 0.0 221420 7980 ? SLl 14:01 0:00 ./howdies bobby 26687 0.2 0.0 221420 7980 ? SLl 14:01 0:00 ./howdies bobby 26688 0.1 0.0 221420 7988 ? SLl 14:01 0:00 ./howdies bobby 26702 0.0 0.0 86004 1668 ? S 14:02 0:00 sshd: bobby@notty bobby 26703 0.0 0.0 65584 976 ? Rs 14:02 0:00 ps u -u bobby ----- Node n023: USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND bobby 22127 0.1 0.0 65908 1332 ? Ss 14:01 0:00 -bash bobby 22128 0.0 0.0 13284 804 ? S 14:01 0:00 pbs_demux bobby 22183 0.0 0.0 64332 1160 ? S 14:01 0:00 /bin/bash /var/spool/... bobby 22190 0.1 0.0 83004 3956 ? S 14:01 0:00 mpiexec -n 8 -machinefile /var/spool/torque/aux//1754949.n131.localdomain ./howdies bobby 22191 0.2 0.0 221420 7988 ? SLl 14:01 0:00 ./howdies bobby 22192 0.2 0.0 221420 7976 ? SLl 14:01 0:00 ./howdies bobby 22193 0.1 0.0 221420 7984 ? SLl 14:01 0:00 ./howdies bobby 22194 0.1 0.0 221420 7980 ? SLl 14:01 0:00 ./howdies bobby 22205 0.0 0.0 86004 1668 ? S 14:02 0:00 sshd: bobby@notty bobby 22206 2.0 0.0 65576 976 ? Rs 14:02 0:00 ps u -u bobby
Special Cases
Exclusive Access
Because Kodiak is a multi-user system, it is possible that your job will share a compute node with another user's job if your job doesn't explicitly request all of the processors on the node. But what if your program is very memory intensive and you need to run fewer processes on a node? You can specify -l nodes=4:ppn=2 and run just 2 processes each on 4 different nodes (8 processes total). Unfortunately, although your job only will only run 2 processes on each node, the batch system sees that there are still 6 unused processors on the nodes, and can assign them to other, possibly memory intensive, jobs. This defeats the purpose of specifying fewer processors per node.
Instead, to get exclusive access to a node, you need to force the batch system to allocate all 8 processors on node by specifying ppn=8. If we specify -l nodes=2:ppn=8, we get a $PBS_NODEFILE that looks like the following:
n001
n001
n001
n001
n001
n001
n001
n001
n002
n002
n002
n002
n002
n002
n002
n002
Calling mpiexec -np 16 -machinefile $PBS_NODEFILE ..., the first process (rank 0) will run on the first host listed in the file (n001), the second process (rank 1) will run on the second host listed (also n001), etc. The ninth process (rank 8) will run on the ninth host listed (now n002), etc. If there are fewer lines in the machinefile than the specified number of processes (-np value), mpiexec will start back at the beginning of the list. If the machine file looked like the following:
n001
n002
The first process (rank 0) will run on host n001, the second (rank 1) will run on host n002, the third (rank 2) will run on host n001, the fourth (rank 3) will run on host n002, and so on. So all we have to do is call
mpiexec -np 8 -machinefile $PBS_NEW_NODEFILE
and 4 processes will run on n001 and 4 will run on n002. But because the batch system has reserved all 8 processors on n001 and n002 for our job, no other jobs will be running on the nodes. Our job will have exclusive access, which is what we want. So how do we turn the original $PBS_NODEFILE, created by the batch system, into our trimmed down version? One simple way would be to use the sort -u command to sort the file "uniquely", thus keeping one entry for each host.
PBS_NEW_NODEFILE=$PBS_O_WORKDIR/trimmed_machinefile.dat
sort -u $PBS_NODEFILE > $PBS_NEW_NODEFILE
mpiexec -np 8 -machinefile $PBS_NEW_NODEFILE
Because modifying the $PBS_NODEFILE itself will cause problems with the batch system you should always create a new machine file and use it instead.
Multi-threaded Programs
If your program is multi-threaded, either explicitly by using OpenMP or POSIX threads, or implicitly by using a threaded library such as the Intel Math Kernel Library (MKL), be careful not to have too many threads executing concurrently. You will need to specify the number of processes per node but launch fewer or just one process. This is similar to method described in the "exclusive access" section above. Because each thread runs on a separate processor, you will need to tell the batch system how many processors to allocate to your process.
By default, OpenMP and MKL will use all of the processors on a node (currently 8). If, for some reason, you want to decrease the number of threads, you can do so by setting environment variables within the shell script that you submit via qsub. The threaded MKL library uses OpenMP internally for threading, so you can probably get by with modifying just the OpenMP environment variable.
OMP_NUM_THREADS=4
export OMP_NUM_THREADS
MKL_NUM_THREADS=4
export MKL_NUM_THREADS
You can also set the number of threads at runtime within your code.
// C/C++
#include "mkl_service.h"
mkl_set_num_threads(4);
! Fortran
use mkl_service
call mkl_set_num_threads(4)
Below is a trivial, multi-threaded (OpenMP) program, "thready". All it does is display the number of threads that will be used and initializes the values of an array. Then, in the parallel region, each thread modifies a specific value of the array and then sleeps for two minutes. After exiting the parallel region, we display the new (hopefully correct) values of the array. The program is compiled with the Intel C compiler icc with the -openmp option.
$cat thready.c#include #define MAX 8 int main(int argc, char **argv) { int i, arr[MAX]; int num; num = omp_get_max_threads(); printf("Howdy! We're about to split into %d threads...\n", num); for (i=0; iicc -openmp -o thready thready.c $./threadyHowdy! We're about to split into 4 threads... Before: arr[0] = -1 arr[1] = -1 arr[2] = -1 arr[3] = -1 arr[4] = -1 arr[5] = -1 arr[6] = -1 arr[7] = -1 After: arr[0] = 0 arr[1] = 1 arr[2] = 2 arr[3] = 3 arr[4] = -1 arr[5] = -1 arr[6] = -1 arr[7] = -1
Next we need to submit the thready program. For this example, we want it to use 4 threads so we call qsub with a -l nodes=1:ppn=4 option to reserve 4 processors for our threads.
$cat thready.sh#!/bin/bash cd $PBS_O_WORKDIR echo "Node(s):" sort -u $PBS_NODEFILE echo export OMP_NUM_THREADS=4 echo "OMP_NUM_THREADS: $OMP_NUM_THREADS" echo echo "Job starting at `date`" echo ./thready echo echo "Job finished at `date`" $qsub -l nodes=1:ppn=4 thready.sh1755333.n131.localdomain $tail thready.sh.o1755333Node(s): n005 OMP_NUM_THREADS: 4 Job starting at Wed Dec 18 11:35:32 CST 2013
Now let's make sure that the process and threads running on the compute node are what we expect. We can see that the job is running on node n005. If we run the ps -f -C thready command on node n005, we can see that only one instance of the thready program is running. The only useful information is that its PID (process ID) is 27934. But if we add the -L option to the ps command, we can also get information about the threads.
$ssh n005 ps -f -C threadyUID PID PPID C STIME TTY TIME CMD bobby 27934 27931 0 10:22 ? 00:00:00 ./thready $ssh n005 ps -f -L -C threadyUID PID PPID LWP C NLWP STIME TTY TIME CMD bobby 27934 27931 27934 0 5 10:22 ? 00:00:00 ./thready bobby 27934 27931 27935 0 5 10:22 ? 00:00:00 ./thready bobby 27934 27931 27936 0 5 10:22 ? 00:00:00 ./thready bobby 27934 27931 27937 0 5 10:22 ? 00:00:00 ./thready bobby 27934 27931 27938 0 5 10:22 ? 00:00:00 ./thready
The LWP column above is the "lightweight process" ID (i.e., thread ID) and we can see that the thready process (PID 27934) has a total of 5 threads. The NLWP (number of lightweight processes) column confirms it. But why are there 5 threads instead of 4 threads which was specified? Notice that the first thread has the same thread ID as its process ID. That is the master or main thread, which is created when the program first starts and will exist until the program exits. When the program reaches the parallel region, the other 4 threads are created and do their work while the main thread waits. At that point, there are 5 theads total. When the program finishes with the parallel region, the 4 threads are terminated and the master thread continues.
Interactive Sessions
Occasionally, you may need to log in to a compute node. Perhaps you want to run top or ps to check the status of a job submitted via qsub. In that case, you can simply ssh to the compute node. But there may be times where you need to do interactive work that is more compute intensive. Although you could just ssh to some arbitrary compute node and start working, this is ill-advised because there may be other jobs already running on that node. Not only would those jobs affect your work, your work would affect those jobs.
Instead, you should use the interactive feature of qsub by including the -I option. This will use the batch system to allocate a node (or nodes) and a processor (or processors) just like you would for a regular, non-interactive job. The only difference is that once the requested resources are available, you will be automatically logged into the compute node and get a command prompt. The "batch" job will exist until you exit or log out from the interactive session.
[bobby@n130 ~]$qsub -Iqsub: waiting for job 1832724.n131.localdomain to start qsub: job 1832724.n131.localdomain ready [bobby@n066 ~]$toptop - 15:47:36 up 102 days, 23:20, 0 users, load average: 7.50, 7.19, 7.57 Tasks: 289 total, 9 running, 280 sleeping, 0 stopped, 0 zombie Cpu(s): 55.7%us, 1.0%sy, 0.0%ni, 42.8%id, 0.4%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 16438792k total, 2395964k used, 14042828k free, 162524k buffers Swap: 18490804k total, 438080k used, 18052724k free, 454596k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6715 betty 25 0 1196m 134m 1168 R 99.0 0.8 9:44.35 prog_01a 6801 betty 25 0 1196m 134m 1168 R 99.0 0.8 7:56.28 prog_01a 6832 betty 25 0 1196m 134m 1168 R 99.0 0.8 4:55.46 prog_01a 6870 betty 25 0 1196m 134m 1164 R 99.0 0.8 1:25.80 prog_01a 6919 betty 25 0 1196m 134m 1164 R 99.0 0.8 1:04.84 prog_01a 6923 betty 25 0 1196m 134m 1164 R 99.0 0.8 0:55.40 prog_01a 7014 betty 25 0 1196m 134m 1164 R 99.0 0.8 0:46.67 prog_01a 7075 bobby 15 0 12864 1120 712 R 1.9 0.0 0:00.01 top 1 root 15 0 10344 76 48 S 0.0 0.0 9:44.65 init 2 root RT -5 0 0 0 S 0.0 0.0 0:00.82 migration/0 3 root 34 19 0 0 0 S 0.0 0.0 0:00.13 ksoftirqd/0 4 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/0 5 root RT -5 0 0 0 S 0.0 0.0 0:00.59 migration/1 [bobby@n066 ~]$cat $PBS_NODEFILEn066 [bobby@n066 ~]$exitlogout qsub: job 1832724.n131.localdomain completed [bobby@n130 ~]$
If there aren't enough available nodes, your interactive job will wait in the queue like any other job. If you get tired of waiting, press ^C.
$ qsub -I -l nodes=20:ppn=8 qsub: waiting for job 1832986.n131.localdomain to start^CDo you wish to terminate the job and exit (y|[n])?yJob 1832986.n131.localdomain is being deleted
If you are logged into Kodiak and have enabled X11 forwarding (i.e., logged in with ssh -X bobby@kodiak.baylor.edu from a Mac or Linux system, or have enabled SSH X11 forwarding option in Putty for Windows) you can run X11 options when logged into a compute node interactively. Because X11 from a compute node (or Kodiak's login node) can be slow, you typically won't want to do this. But there may be times when it is required, for example, when you need to run MATLAB interactively, or need to debug a program with a graphical debugger. This assumes you are running an X server (XQuartz for Mac, or Cygwin/X or Xming on Windows) on your desktop system.
First, on the Kodiak login node, make sure that X11 is, in fact, working. The xlogo and xmessage commands are a simple way to test this.
$echo $DISPLAYlocalhost:10.0 $xlogo &[1] 9927 $echo 'Howdy from node' `hostname` | xmessage -file - &[2] 9931
If you are sure that X11 works from the login node, start an interactive session, as above, but add a -X to tell qsub that you wish to forward X11 from the compute node.
[bobby@n130 howdy]$qsub -I -Xqsub: waiting for job 2444343.n131.localdomain to start qsub: job 2444343.n131.localdomain ready [bobby@n083 ~]$echo 'Howdy from node' `hostname` | xmessage -file -
[bobby@n083 ~]$ exit qsub: job 2444343.n131.localdomain completed [bobby@n130 howdy]$
Multiple Job Submissions
There may be times where you want to run, or at least submit, multiple jobs at the same time. For example, you may want to run your program with varying input parameters. You could submit each job individually, but if there are many jobs, this might be problematic.
Job Arrays
If each run of your program has the same resource requirements, that is, the same number of nodes and processors, you can run multiple jobs as a job array. Below is a trivial program that simply outputs a word passed to it at the command line.
$ cat howdy2.c
#include
int main(int argc, char **argv)
{
if (argc == 2)
{
printf("Howdy! You said, "%s".\n", argv[1]);
}
else
{
printf("Howdy!\n");
}
}
What we want to do is run the program three times, each with a different word. To run this as a job array, add the -t option along with a range of numbers to the qsub command. For example, qsub -t 0-2 array_howdy.sh. This command will submit the array_howdy.sh script three times but with an extra environment variable, $PBS_ARRAYID, which will contain a unique value based on the range. You could test the value of $PBS_ARRAYID and run your program with different arguments.
$ cat array_howdy.sh
#!/bin/sh
#PBS -o array.out
#PBS -e array.err
cd $PBS_O_WORKDIR
if [ $PBS_ARRAYID == 0 ]
then
./howdy2 apple
elif [ $PBS_ARRAYID == 1 ]
then
./howdy2 banana
elif [ $PBS_ARRAYID == 2 ]
then
./howdy2 carrot
fi
For a more complex real-world program, you might have multiple input files named howdy_0.dat through howdy_N.dat. Instead of an unwieldy if-then-elif-elif-elif-etc construct, you could use $PBS_ARRAYID to specify an individual input file and then use a single command to launch your program.
$ls inputhowdy_0.dat howdy_1.dat howdy_2.dat $cat input/howdy_0.datapple $cat input/howdy_1.datbanana $cat input/howdy_2.datcarrot $cat array_howdy.sh#!/bin/sh #PBS -o array.out #PBS -e array.err cd $PBS_O_WORKDIR DATA=`cat ./input/howdy_$PBS_ARRAYID.dat` ./howdy2 $DATA
When you submit your job as a job array, you will see a slightly different job id, one with "[]" appended to it. This job id represents all of the jobs in the job array. For individual jobs, specify the array id within the brackets (e.g., 123456[0]). Normally, qstat will display one entry for the job array. To see all of them, add a -t option.
The job array's output and error files will be named jobname.o-#, where # is replaced by the individual job array id numbers.
$qsub -t 0-2 array_howdy.sh2462930[].n131.localdomain $qstat -u bobbyn131.localdomain: Job ID Username Queue Jobname -------------------- ----------- -------- ---------------- ... 2462930[].n131.l bobby batch array_howdy.sh $qstat -t -u bobbyn131.localdomain: Job ID Username Queue Jobname -------------------- ----------- -------- ---------------- ... 2462930[0].n131. bobby batch array_howdy.sh-1 2462930[1].n131. bobby batch array_howdy.sh-2 2462930[2].n131. bobby batch array_howdy.sh-3 $ls array.out*array.out-0 array.out-1 array.out-2 $cat array.out-0Howdy! You said, "apple". $cat array.out-1Howdy! You said, "banana". $cat array.out-2Howdy! You said, "carrot".
Sequential, Non-concurrent Jobs
When you submit a job array as above, all of the individual jobs will run as soon as possible. But there may be times where you don't want them all to run concurrently. For example, the output of one job might be needed as the input for the next. Or perhaps you want this program to run, but not at the expense of some other, higher priority program you also need to run. Whatever the reason, you can limit the number of jobs that can run simultaneously by adding a slot limit to the -t option. For example, qsub -t 0-9%1 will create a job array with 10 jobs (0 through 9) but only 1 will run at a time. The others will wait in the queue until the one that is running finishes. When running qstat, you can see that the status of each non-running job is H (held) as opposed to Q (queued).
$qsub -t 0-2%1 array_howdy.sh2463526[].n131.localdomain $qstat -t -u bobbyn131.localdomain: Job ID Username Queue Jobname S Time -------------------- ----------- -------- ---------------- ... - ----- 2463526[0].n131. bobby batch array_howdy.sh-0 R -- 2463526[1].n131. bobby batch array_howdy.sh-1 H -- 2463526[2].n131. bobby batch array_howdy.sh-2 H --
This works if you can run your job as a job array. But what if it can't? For example, you may want to submit multiple jobs but if each requires a different number of nodes or processors then a job array won't work. You will need to qsub the jobs individually. You might be tempted to add a qsub command at the end of your submitted script. However, this will not work because the script runs on the compute nodes but the qsub command only works on Kodiak's login node. Instead, to have a job wait on another job to finish before starting, you add a -W ("additional attributes") option to the qsub to specify a job dependency for the new job. The general format for the -W option is:
qsub -W attr_name=attr_list ...
There are several possible attr_names that can be specified as additional attributes. In this case, the attribute name we want to use is "depend", the attribute list is the type of dependency ("after" or "afterok"), and the depend argument (the id of the job we are waiting on). The difference between after and afterok is that with the former, the new job will start when the first one finishes, not matter what the reason; with the latter, the new job will start only if the first one finished successfully, and returned a 0 status. So the full option will be:
qsub -W depend=after:job_id ...
For the job id, you can use either the full job id (e.g., 123456.n131.localdomain) or just the number part.
$cat howdies.sh#!/bin/bash #PBS -o howdies.out #PBS -e howdies.err #PBS -N howdies module purge module load mvapich2/1.9-gcc-4.9.2 cd $PBS_O_WORKDIR echo "------------------" echo echo "Job id: $PBS_JOBID" echo num=`cat $PBS_NODEFILE | wc -l` echo "Total processes: $num" echo echo "Job starting at `date`" echo mpiexec -n $num -machinefile $PBS_NODEFILE ./howdies echo echo "Job finished at `date`" echo $qsub -l nodes=1:ppn=8 howdies.sh2463553.n131.localdomain $qsub -l nodes=1:ppn=4 -W depend=afterok:2463553.n131.localdomain howdies.sh2463555.n131.localdomain $qsub -l nodes=1:ppn=2 -W depend=afterok:2463555.n131.localdomain howdies.sh2463556.n131.localdomain $qsub -l nodes=1:ppn=1 -W depend=afterok:2463556.n131.localdomain howdies.sh2463557.n131.localdomain $qstat -u bobbyn131.localdomain: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time ----------------- --------- -------- --------- ------ --- --- ------ ----- - ----- 2463553.n131.loc bobby batch howdies 10460 1 8 -- 5000: R 00:00 2463555.n131.loc bobby batch howdies -- 1 4 -- 5000: H -- 2463556.n131.loc bobby batch howdies -- 1 2 -- 5000: H -- 2463557.n131.loc bobby batch howdies -- 1 1 -- 5000: H -- $qstat -u bobbyn131.localdomain: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time ----------------- --------- -------- --------- ------ --- --- ------ ----- - ----- 2463555.n131.loc bobby batch howdies 15434 1 4 -- 5000: R 00:00 2463556.n131.loc bobby batch howdies -- 1 2 -- 5000: H -- 2463557.n131.loc bobby batch howdies -- 1 1 -- 5000: H -- $qstat -u bobbyn131.localdomain: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time ----------------- --------- -------- --------- ------ --- --- ------ ----- - ----- 2463556.n131.loc bobby batch howdies 15525 1 2 -- 5000: R 00:01 2463557.n131.loc bobby batch howdies -- 1 1 -- 5000: H -- $qstat -u bobbyn131.localdomain: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time ----------------- --------- -------- --------- ------ --- --- ------ ----- - ----- 2463557.n131.loc bobby batch howdies 15613 1 1 -- 5000: R 00:04 $cat howdies.out------------------ Job id: 2463553.n131.localdomain Total processes: 8 Job starting at Thu Jan 30 13:48:41 CST 2014 Howdy! This is rank 7 of 8 running on n017 Howdy! This is rank 1 of 8 running on n017 Howdy! This is rank 5 of 8 running on n017 Howdy! This is rank 4 of 8 running on n017 Howdy! This is rank 6 of 8 running on n017 Howdy! This is rank 2 of 8 running on n017 Howdy! This is rank 3 of 8 running on n017 Howdy! This is rank 0 of 8 running on n017 Job finished at Thu Jan 30 13:53:43 CST 2014 ------------------ Job id: 2463555.n131.localdomain Total processes: 4 Job starting at Thu Jan 30 13:53:44 CST 2014 Howdy! This is rank 3 of 4 running on n082 Howdy! This is rank 0 of 4 running on n082 Howdy! This is rank 1 of 4 running on n082 Howdy! This is rank 2 of 4 running on n082 Job finished at Thu Jan 30 13:58:46 CST 2014 ------------------ Job id: 2463556.n131.localdomain Total processes: 2 Job starting at Thu Jan 30 13:58:47 CST 2014 Howdy! This is rank 1 of 2 running on n082 Howdy! This is rank 0 of 2 running on n082 Job finished at Thu Jan 30 14:03:49 CST 2014 ------------------ Job id: 2463557.n131.localdomain Total processes: 1 Job starting at Thu Jan 30 14:03:50 CST 2014 Howdy! This is rank 0 of 1 running on n082 Job finished at Thu Jan 30 14:08:52 CST 2014
MATLAB
When you run MATLAB on your local computer, you may be used to seeing the MATLAB "desktop" window with its various panels, such as the command window where you enter commands, the list of files in the current folder, etc. If you wish, you can run MATLAB interactively on the Kodiak login node and use the desktop window to edit scripts, view plots, etc. However, do not run MATLAB on the login node to do actual, compute intensive, work. Instead, you need to submit a MATLAB script to run on a compute node like other programs. Because the script is non-interactive, you will need to remove any code that requires an interactive display such as plot().
Note: As was described above, you could use the qsub -X command to create an X11-enabled interactive session on a compute node. This would allow you to run the the MATLAB desktop interactively.
Below is a trivial MATLAB script (.m file) that just adds two numbers and displays the result. Normally, you would run MATLAB, navigate to the directory containing this script, and then at the >> prompt, run howdy. MATLAB would then look for the file "howdy.m" and execute it.
>>pwdans = /home/bobby/howdy >>ls *.mhowdy.m >>type howdy.mn = 1 + 2; disp(sprintf('Howdy! 1 + 2 = %d', n)) >>howdyHowdy! 1 + 2 = 3 >>
So how do we do this on a compute node? To run MATLAB from a command line prompt (or in this case, a shell script) we first need to disable the GUI interface with the -nodisplay -nodesktop -nosplash options. The -nodisplay option should implicitly disable the other two but we'll go ahead and add them anyway. For many tasks, including this example, we won't need Java, so to decrease memory usage and start MATLAB quicker, we'll add the -nojvm option. So the command to run MATLAB is:
matlab -nodisplay -nodesktop -nosplash -nojvm
To tell MATLAB to run our howdy.m script, we need to have it execute the howdy command. We do that with the -r option:
matlab -nodisplay -nodesktop -nosplash -nojvm -r 'howdy'
It is important to remember that the argument that you include with the -r option is the MATLAB command and not a file name. Recall that within MATLAB, if you enter "foo" at the ">>" prompt, MATLAB will look for a file named "foo.m". If you were to try to run "foo.m" it would look for the file "foo.m.m" and display an "Undefined variable or function" error. Also, the single quotes surrounding the argument aren't necessary if it is just one word command like "howdy" but it doesn't hurt to use them.
One other option we need to set is -singleCompThread. Some features of MATLAB are multi-threaded and by default MATLAB will use all of the processors on the compute node. The -singleCompThread forces MATLAB to use only one processor. So now, the command is:
matlab -nodisplay -nodesktop -nosplash -nojvm -singleCompThread -r 'howdy'
In the shell script that we submit via qsub, we must change our directory to wherever the howdy.m script file is. For this example, the howdy.m file is in the same directory as our submitted shell script, so we just need to cd $PBS_O_WORKDIR.
$cat howdy.mn = 1 + 2; disp(sprintf('Howdy! 1 + 2 = %d', n)) $cat matlab_howdy.sh#!/bin/bash cd $PBS_O_WORKDIR matlab -nodisplay -nodesktop -nosplash -nojvm -singleCompThread -r howdy $qsub matlab_howdy.sh1827767.n131.localdomain $cat matlab_howdy.sh.o1827767< M A T L A B (R) > Copyright 1984-2012 The MathWorks, Inc. R2012a (7.14.0.739) 64-bit (glnxa64) February 9, 2012 To get started, type one of these: helpwin, helpdesk, or demo. For product information, visit www.mathworks.com. Howdy! 1 + 2 = 3 >>
Parallel MATLAB
Below is a trivial MATLAB script that uses a parallel parfor loop. It first creates a parallel pool with the maximum possible number of tasks (i.e., 8), then prints out information from within the parfor loop, closes the pool, and finally quits.
Note: This script uses matlabpool, which is required for the version of MATLAB currently installed on Kodiak (R2012a). More recent MATLAB versions use parpool instead.
$ cat howdies.m
if (matlabpool('size') == 0)
matlabpool open local
end
pool_size = matlabpool('size');
parfor i = 1:16
task_id = get(getCurrentTask, 'ID');
disp(sprintf('Howdy! This is task ID %d of %d. i == %d', task_id, pool_size, i))
end
matlabpool close
quit
The maximum number of tasks is the number of processors/cores on a single node. (A parfor loop will not use multiple nodes.) Like other multi-threaded programs, we want to batch system to assign all of the processors on the node to our MATLAB program, so we need submit the job with the -l nodes=1:ppn=8 option.
In the past, you could specify the number of threads that MATLAB should use with maxNumCompThreads but this feature is being removed from MATLAB. So the number of tasks/threads now can be either 1 (by specifying the -singleCompThread option) or all (by not specifying the -singleCompThread option). We want more than 1 thread so we won't use -singleCompThread. Also, the matlabpool feature requires Java, so we need to remove the -nojvm option as well.
$cat matlab_howdies.sh#!/bin/bash #PBS -l nodes=1:ppn=8 cd $PBS_O_WORKDIR matlab -nodisplay -nodesktop -nosplash -r howdies $qsub matlab_howdies.sh2306374.n131.localdomain $cat matlab_howdies.sh.o2306374Warning: No window system found. Java option 'MWT' ignored < M A T L A B (R) > Copyright 1984-2012 The MathWorks, Inc. R2012a (7.14.0.739) 64-bit (glnxa64) February 9, 2012 To get started, type one of these: helpwin, helpdesk, or demo. For product information, visit www.mathworks.com. Starting matlabpool using the 'local' profile ... connected to 8 labs. Howdy! This is task ID 1 of 8. i == 2 Howdy! This is task ID 1 of 8. i == 1 Howdy! This is task ID 2 of 8. i == 4 Howdy! This is task ID 2 of 8. i == 3 Howdy! This is task ID 3 of 8. i == 6 Howdy! This is task ID 3 of 8. i == 5 Howdy! This is task ID 4 of 8. i == 8 Howdy! This is task ID 4 of 8. i == 7 Howdy! This is task ID 5 of 8. i == 9 Howdy! This is task ID 6 of 8. i == 10 Howdy! This is task ID 7 of 8. i == 11 Howdy! This is task ID 8 of 8. i == 12 Howdy! This is task ID 5 of 8. i == 13 Howdy! This is task ID 6 of 8. i == 14 Howdy! This is task ID 5 of 8. i == 15 Howdy! This is task ID 7 of 8. i == 16 Sending a stop signal to all the labs ... stopped.
There is an issue you may encounter if you try to run multiple, parallel MATLAB programs simultaneously. MATLAB writes temporary files related to the job in a hidden directory within your home directory. (The directory is "~/.matlab/local_cluster_jobs/[version]/".) The problem is that multiple jobs running simultaneously will each try to write to the same files in that directory which can corrupt the files, or at least, prevent the MATLAB parallel pool from starting up. The solution is to create a separate, unique, directory when the job runs and tell MATLAB to use that.
The shell script below creates a directory, based upon the job's Job Id number, so it will be unique. It sets (and exports) the $MATLAB_WORKDIR environment variable so that MATLAB can use it.
$lspartest.m partest.sh $cat partest.sh#!/bin/bash #PBS -l nodes=1:ppn=8 module purge module load matlab/2015a cd $PBS_O_WORKDIR echo "Requested node(s):" uniq $PBS_NODEFILE echo # Create the temporary matlab work directory for the parallel job. Normally, # matlab will use a directory within $HOME/.matlab. Instead, we'll use the # directory $HOME/matlab_work/temp_jobnum (where jobnum is the number part # of this job's Job ID). We'll delete it before exiting. # Parse the Job ID and remove the ".n131.localdomain" bit. Only works with # the bash shell. JOBID_NUM=${PBS_JOBID%%.*} MATLAB_WORKDIR=$HOME/matlab_work/temp_$JOBID_NUM echo "Creating MATLAB work directory: $MATLAB_WORKDIR" # If it already exists, something is wrong. if [ -d $MATLAB_WORKDIR ] then echo "Directory already exists. Exiting..." exit fi # Create it with -p option to create matlab_work parent dir if necessary. mkdir -p $MATLAB_WORKDIR # Make sure it actually got created. if [ ! -d $MATLAB_WORKDIR ] then echo "Could not create directory. Exiting..." exit fi # Export the environment variable so matlab can use it. export MATLAB_WORKDIR # Do that matlab thing. echo "Running matlab..." matlab -nodisplay -nodesktop -nosplash -r partest # Delete the temp directory. (Don't delete the matlab_work parent directory # because another job may be using it.) echo "Removing MATLAB work directory: $MATLAB_WORKDIR" rm -rf $MATLAB_WORKDIR echo "All done."
The shell script above runs the following parallel MATLAB script. The script uses the exported $MATLAB_WORKDIR environment variable as the "job storage location" value for the parallel pool.
$ cat partest.m
matlab_workdir = getenv('MATLAB_WORKDIR')
if (isempty(matlab_workdir))
disp('Work directory ($MATLAB_WORKDIR) not defined.');
quit
end
disp(sprintf('Work directory: %s', matlab_workdir));
disp('Contents before:');
dir(matlab_workdir);
% Create a matlab cluster based on 'local' profile. Then set the
% cluster's work directory to our matlab_workdir.
the_cluster = parcluster('local')
the_cluster.JobStorageLocation = matlab_workdir
% Create a parpool with our cluster and get the # of workers.
the_pool = parpool(the_cluster, 8)
num_workers = the_pool.NumWorkers
disp('Contents during:');
dir(matlab_workdir);
% Pause for 2 minutes to allow user to check directory, etc.
disp('Pausing 120 seconds...');
pause(120);
disp('...Done.');
% Create an array and use parfor to set its contents. (Just set the
% value to the task ID of the parallel task running that iteration.)
arr = zeros(1,num_workers)
parfor i = 1:num_workers
task_id = get(getCurrentTask, 'ID');
arr(:,i) = task_id;
end
arr
% Delete the parpool pool object. This should delete some, but not all,
% of the files in the work directory. Technically, this isn't necessary
% since we will delete the directory outside of the this script when it
% quits, but it's best to do things the right way.
delete(the_pool);
disp('Contents after:');
dir(matlab_workdir);
quit
Now let us submit the job three times. This should create three unique directories within $HOME/matlab_workdir, run the MATLAB script, and delete the directories when finished.
$qsub -l nodes=1:ppn=8 partest.sh3294581.n131.localdomain $qsub -l nodes=1:ppn=8 partest.sh3294582.n131.localdomain $qsub -l nodes=1:ppn=8 partest.sh3294583.n131.localdomain $qstat -u bobbyn131.localdomain: Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time ----------------- --------- -------- ---------- ------ --- --- ------ ----- - ----- 3294581.n131.loc bobby batch partest.sh 4665 1 8 -- 5000: R 00:05 3294582.n131.loc bobby batch partest.sh 20854 1 8 -- 5000: R 00:04 3294583.n131.loc bobby batch partest.sh 1511 1 8 -- 5000: R 00:04 $ls -F ~/matlab_worktemp_3294581/ temp_3294582/ temp_3294583/ $lspartest.m partest.sh.e3294581 partest.sh.e3294583 partest.sh.o3294582 partest.sh partest.sh.e3294582 partest.sh.o3294581 partest.sh.o3294583 $cat partest.sh.o3294581Requested node(s): n038 Creating MATLAB work directory: /home/bobby/matlab_work/temp_3294581 Running matlab... < M A T L A B (R) > Copyright 1984-2015 The MathWorks, Inc. R2015a (8.5.0.197613) 64-bit (glnxa64) February 12, 2015 To get started, type one of these: helpwin, helpdesk, or demo. For product information, visit www.mathworks.com. Academic License matlab_workdir = /home/bobby/matlab_work/temp_3294581 Work directory: /home/bobby/matlab_work/temp_3294581 Contents before: . .. the_cluster = Local Cluster Properties: Profile: local Modified: false Host: n038 NumWorkers: 8 JobStorageLocation: /home/bobby/.matlab/local_cluster_jobs/R2015a RequiresMathWorksHostedLicensing: false Associated Jobs: Number Pending: 0 Number Queued: 0 Number Running: 0 Number Finished: 0 the_cluster = Local Cluster Properties: Profile: local Modified: true Host: n038 NumWorkers: 8 JobStorageLocation: /home/bobby/matlab_work/temp_3294581 RequiresMathWorksHostedLicensing: false Associated Jobs: Number Pending: 0 Number Queued: 0 Number Running: 0 Number Finished: 0 Starting parallel pool (parpool) using the 'local' profile ... connected to 8 workers. the_pool = Pool with properties: Connected: true NumWorkers: 8 Cluster: local AttachedFiles: {} IdleTimeout: 30 minute(s) (30 minutes remaining) SpmdEnabled: true num_workers = 8 Contents during: . Job1.diary.txt Job1.state.mat .. Job1.in.mat matlab_metadata.mat Job1 Job1.jobout.mat Job1.common.mat Job1.out.mat Pausing 120 seconds... ...Done. arr = 0 0 0 0 0 0 0 0 arr = 2 3 6 4 1 7 5 8 Parallel pool using the 'local' profile is shutting down. Contents after: . matlab_metadata.mat .. Removing MATLAB work directory: /home/bobby/matlab_work/temp_3294581 All done.
Mathematica
Below is a trivial Mathematica script (.m file) that just adds two numbers and displays the result.
$ cat mm_howdy.m
n = 1 + 2;
Print[ OutputForm[ "Howdy! 1 + 2 = " <> ToString[ n ] ] ];
To run a Mathematica script on a compute node, we need to add the -noprompt option and specify the script as the argument to the -script option. Unlike MATLAB, which you specify a command (which implicitly finds the file) this argument is the script file itself.
math -noprompt -script mm_howdy.m
Because some of Mathematica's functions and features are implicitly multi-threaded, you will need to specify -l nodes=1:ppn=8 when you submit qsub so that all of the processors on that node will be assigned to your job.
$cat mm_howdy.sh#!/bin/bash #PBS -l nodes=1:ppn=8 cd $PBS_O_WORKDIR math -noprompt -script mm_howdy.m $qsub mm_howdy.sh2362939.n131.localdomain $cat mm_howdy.sh.o2362939Howdy! 1 + 2 = 3
Because a job that requests 8 processors is more likely to wait in the batch queue that one that requests just 1 processor, if you know that your script will not need all 8 processors, you may want to force Mathematica to use just a single processor. Unlike MATLAB, where you can do this by adding a -singleCompThread option in your submitted shell script, Mathematica requires you to modify the Mathematica script (.m file) itself. Mathematica uses the Intel Math Kernel Library (MKL) internally, so you could add export MKL_NUM_THREADS=4 to your submitted shell script. But because you also have to set another option within your Mathematica script, it may be easier to set the MKL threads there as well.
SetSystemOptions["ParallelOptions" -> "ParallelThreadNumber" -> 1];
SetSystemOptions["MKLThreads" -> 1];
Unlike MATLAB which will either use 1 or all (8) processors, with Mathematica you can use the above lines to specify an arbitrary number of threads in parallel regions of the code. Make sure that the number of threads matches the number of processors specified with the -l nodes=1:ppn=N option. You can use the environment variable PBS_NUM_PPN that is set by the batch system and available on the compute node. Environment variables are strings, so you will need to convert them to an expression before assigning it.
numThreads = ToExpression[ Environment["PBS_NUM_PPN"] ]
SetSystemOptions["ParallelOptions" -> "ParallelThreadNumber" -> numThreads];
SetSystemOptions["MKLThreads" -> numThreads];
Creating images, e.g., with Plot[] or Graphics3d[], requires an X11 front-end even if you are just exporting the image to a file. This will not work in batch so you will need to move your graphics code to a separate, interactive script.
R
Note: There are multiple versions of R installed on Kodiak. Use the module load command to specify which one you want to use. This document assumes R/3.2.0.
To run an "R" program non-interactively, you specify the .R script with the --file option, e.g.,
R --file=FILE
The command above will take input from the file named "FILE", execute the statements within, and then exit. One of the features of R is the ability to save/restore a session's workspace, variables, etc. It implements this with a file (default name ".RData") in the current directory. When you submit an R program as a job in the batch system, you may want to run the R script with a "clean slate7quot; by including the following options:
--no-restore |
Don't restore previously saved workspace, objects, variables, etc. |
--no-site-file |
Don't run the site-wide R profile startup script. |
--no-init-file |
Don't run the user's R profile startup script. |
--no-environ |
Don't read the site and user environment files. |
--no-save |
Don't save the workspace at the end of the session. |
Fortunately, there is a --vanilla "shortcut" option that combines all 5 of the above options. Even with the --vanilla (or above options) you can still explicitly load and save your workspace from within your R program with the load() and save.image() functions (as well as q(save="yes")).
Below is a trivial R program (.R file) that just adds two numbers and displays the result. Because we will be running R with --vanilla the q(save="no") at the end of the program is actually unnecessary.
$cat howdy.Rn <- 1 + 2 cat("Howdy! 1 + 2 =", n, "\n") q(save="no") $cat r_howdy.sh#!/bin/sh #PBS -l nodes=1:ppn=1 module purge module load R/3.2.0 cd $PBS_O_WORKDIR R --vanilla --file=howdy.R $qsub r_howdy.sh2444304.n131.localdomain $cat r_howdy.sh.o2444304R version 3.2.0 (2015-04-16) -- "Full of Ingredients" Copyright (C) 2015 The R Foundation for Statistical Computing Platform: x86_64-unknown-linux-gnu (64-bit) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under certain conditions. Type 'license()' or 'licence()' for distribution details. Natural language support but running in an English locale R is a collaborative project with many contributors. Type 'contributors()' for more information and 'citation()' on how to cite R or R packages in publications. Type 'demo()' for some demos, 'help()' for on-line help, or 'help.start()' for an HTML browser interface to help. Type 'q()' to quit R. > n <- 1 + 2 > cat("Howdy! 1 + 2 =", n, "\n") Howdy! 1 + 2 = 3 > > q(save="no")
To suppress R's startup text, run R with the --quiet option. You may have noticed that R will also print out the commands from your R file as they are executed. To suppress those (and the startup text as well), run R with the --slave option.
$cat r_howdy.sh#!/bin/sh #PBS -l nodes=1:ppn=1 module purge module load R/3.2.0 cd $PBS_O_WORKDIR module purge module load R/3.2.0 R --vanilla --slave --file=howdy.R $qsub r_howdy.sh2444305.n131.localdomain $cat r_howdy.sh.o24443045Howdy! 1 + 2 = 3
Normally, R is single-threaded and will only run one one processor. When you submit your R program to the batch system with qsub, you should specify -l nodes=1:ppn=1. If your R program takes advantage of multi-threaded features, for example, using parallel "for" loops or calling libraries linked with the Intel Math Kernel Library (MKL), you will need to specify the number of processors to be equal to the number of threads you plan to use.
R does support parallel programming using the "Rmpi" and "snow" packages. These are currently only available with R version 3.2.0 so you will need to module load R/3.2.0 first. Also, Rmpi was built with OpenMPI 1.6.5, so you will need to module load openmpi/1.6.5 as well.
Note: This is not a tutorial on parallel R programming, Rmpi, or snow. Instead, it is assumed that you are already familiar with these and are looking for information on running your parallel R program on Kodiak.
Below is a simple R program that uses snow and Rmpi. It creates a snow "cluster" and calls the function howdy on each process. (The howdy function just returns the rank, size, and host of the current process.) It then displays the results from the clusterCall, stops the snow "cluster", and quits. You specify the number of processes when creating a cluster with makeCluster(). Although you should be able to get the number of requested processes with mpi.universe.size, this does not work with OpenMPI 1.6.5. Instead, you can get the number using the environment variable $PB_NP, which is set by the batch system when you call qsub.
$lshowdies.R r_howdies.sh $cat howdies.Rlibrary(snow) library(Rmpi) howdy <- function() { myID <- mpi.comm.rank() numProcs <- mpi.comm.size() thisNode <- mpi.get.processor.name() paste("Howdy! This is process ", myID, " of ", numProcs, " running on node ", thisNode) } pbs_np <- Sys.getenv("PBS_NP") theCluster <- makeCluster(pbs_np, type="MPI") howdies <- clusterCall(theCluster, howdy) print(unlist(howdies)) stopCluster(theCluster) q(save = "no")
$ cat r_howdies.sh
#!/bin/sh
#PBS -l nodes=2:ppn=8
module purge
module load openmpi/1.6.5
module load R/3.2.0
cd $PBS_O_WORKDIR
R --vanilla --slave --file=howdies.R
$qsub r_howdies.sh3125885.n131.localdomain $lshowdies.R r_howdies.sh r_howdies.sh.e3125885 r_howdies.sh.o3125885 $cat r_howdies.sh.o312588516 slaves are spawned successfully. 0 failed. [1] "Howdy! This is process 1 of 17 running on node n110" [2] "Howdy! This is process 2 of 17 running on node n110" [3] "Howdy! This is process 3 of 17 running on node n110" [4] "Howdy! This is process 4 of 17 running on node n110" [5] "Howdy! This is process 5 of 17 running on node n110" [6] "Howdy! This is process 6 of 17 running on node n110" [7] "Howdy! This is process 7 of 17 running on node n110" [8] "Howdy! This is process 8 of 17 running on node n109" [9] "Howdy! This is process 9 of 17 running on node n109" [10] "Howdy! This is process 10 of 17 running on node n109" [11] "Howdy! This is process 11 of 17 running on node n109" [12] "Howdy! This is process 12 of 17 running on node n109" [13] "Howdy! This is process 13 of 17 running on node n109" [14] "Howdy! This is process 14 of 17 running on node n109" [15] "Howdy! This is process 15 of 17 running on node n109" [16] "Howdy! This is process 16 of 17 running on node n110" [1] 1
Note: Notice that the size (from mpi.comm.size) is 17 and not 16. Often, an MPI program will run N processes, with rank 0 (of N) doing work along with the other nodes. When you create a "cluster" with snow, it starts N additional processes that do all the work while rank 0 supervises. You could start N-1 processes and have process 0 work along with them.
Debugging
Of course, none of us ever makes mistakes. But sometimes gremlins do log in to Kodiak during the night and sneak errors into our programs. There may be times where we need to run a debugger to track down any problems.
Note: This is not meant to be a tutorial on debugging techniques. The instructions below only cover the very basics of how to run your program within a debugging environment (specifically gdb and Totalview and see where the program crashed. Actual debugging is left as an exercise for the reader.
Below is a modified (those pesky gremlins!) version of howdy.c that causes the program to crash. When we submit it to the batch system, we see that there is nothing in the output file, but there is information, something about a "segmentation fault" in the the error file.
$cat rowdy.c#include void gethost(char *name, int len); int main(int argc, char **argv) { char hostname[80]; /* printf("Sleeping for 5 minutes...\n"); sleep(300); printf("And we're awake.\n"); */ gethost(hostname, 80); printf("Node %s says, "Howdy!"\n", hostname); } void gethost(char *name, int len) { // Set name pointer to an invalid address... name = (char *)(-1); gethostname(name, len); } $qsub rowdy.sh2445857.n131.localdomain $cat rowdy.sh.o2445857$cat rowdy.sh.e2445857/var/spool/torque/mom_priv/jobs/2445857.n131.localdomain.SC: line 1: 18818 Segmentation fault /home/bobby/howdy/rowdy
The first thing we need to do is recompile the program with the -g option. This tells the compiler to include debugging information in the executable program. Because we shouldn't run or debug the program on Kodiak's login node, we'll use qsub to start an interactive session (see above) on one of the compute nodes. We'll then run the program interactively and see that it does, in fact, crash with a segmentation fault.
$gcc -g -o rowdy rowdy.c$qsub -Iqsub: waiting for job 2445868.n131.localdomain to start qsub: job 2445868.n131.localdomain ready [bobby@n121 ~]$cd howdy[bobby@n121 howdy]$./rowdySegmentation fault
gdb
Now we'll use the gdb debugger. At the (gdb) prompt, we enter file rowdy to tell gdb that we want to debug the program rowdy. It then loads the symbols from the executable and then we enter run to launch the program. Once it reaches the spot where the segmentation fault occurs, the debugger then stops and displays the (gdb) prompt. The where (or bt, backtrace) command displays a stack dump which is basically the flow of the program through its functions and subroutines. Here we can see that the main routine calls gethost(), a function in our program, which calls gethostname() and memcpy() which are system routines. Each function call adds a stack frame which we can see are numbered #0 through #3. The segmentation fault actually occurred inside of memcpy() but the bug is probably in our code. We can see that the value of the name pointer variable passed to gethostname() is 0xfffff (or -1) which is an invalid address pointer. That's the ultimate cause of the crash. We then kill the program and quit.
[bobby@n121 howdy]$gdbGNU gdb (GDB) Red Hat Enterprise Linux (7.0.1-37.el5_7.1) Copyright (C) 2009 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-redhat-linux-gnu". For bug reporting instructions, please see: . (gdb)file rowdyReading symbols from /home/bobby/howdy/rowdy...done. (gdb)runStarting program: /home/bobby/howdy/rowdy Program received signal SIGSEGV, Segmentation fault. 0x0000003d0e87b441 in memcpy () from /lib64/libc.so.6 (gdb)where#0 0x0000003d0e87b441 in memcpy () from /lib64/libc.so.6 #1 0x0000003d0e8cc475 in gethostname () from /lib64/libc.so.6 #2 0x0000000000400542 in gethost ( name=0xffffffffffffffff
, len=80) at rowdy.c:17 #3 0x0000000000400505 in main (argc=1, argv=0x7fffffffde48) at rowdy.c:9 (gdb) frame 2 #2 0x0000000000400542 in gethost ( name=0xffffffffffffffff, len=80) at rowdy.c:17 (gdb) print len $1 = 80 (gdb) print name $2 = 0xffffffffffffffff
(gdb) kill Kill the program being debugged? (y or n) y (gdb) quit [bobby@n121 howdy]$ exit qsub: job 2445868.n131.localdomain completed
If your program is currently running and you need to debug it for some reason, you can use gdb to attach to the running process using its process id (PID). Since your program has already been submitted to the batch system and is running on a node, you should just ssh to the node. (If you were to use qsub to create an interactive session as above, you might be assigned a different compute node than the compute node that your job is running on.)
In the rowdy.c program above, we've uncommented the segment of code that sleeps for 5 minutes, simulating the program doing actual work. This also gives us a chance to log in to the compute node and attach gdb to the process.
[bobby@n130 howdy]$qsub rowdy.sh2447704.n131.localdomain [bobby@n130 howdy]$qstat -n -u bobbyn131.localdomain: Job ID Username Queue Jobname -------------------- ----------- -------- ---------------- ... 2447704.n131.loc bobby batch rowdy.sh n083/0 [bobby@n130 howdy]$ssh n083Last login: Thu Jan 16 16:14:16 2014 from 192.168.1.130 [bobby@n083 ~]$ps -u bobbyPID TTY TIME CMD 27261 ? 00:00:00 bash 27316 ? 00:00:00 bash 27318 ? 00:00:00 rowdy 27321 ? 00:00:00 sshd 27322 pts/0 00:00:00 bash 27381 pts/0 00:00:00 ps [bobby@n083 ~]$/usr/bin/gdbGNU gdb Fedora (6.8-27.el5) Copyright (C) 2008 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-redhat-linux-gnu". (gdb)attach 27318Attaching to process 27318 Reading symbols from /home/bobby/howdy/rowdy...done. Reading symbols from /lib64/libc.so.6...done. Loaded symbols for /lib64/libc.so.6 Reading symbols from /lib64/ld-linux-x86-64.so.2...done. Loaded symbols for /lib64/ld-linux-x86-64.so.2 0x00000038b3299730 in __nanosleep_nocancel () from /lib64/libc.so.6 (gdb)where#0 0x00000038b3299730 in __nanosleep_nocancel () from /lib64/libc.so.6 #1 0x00000038b3299584 in sleep () from /lib64/libc.so.6 #2 0x00000000004005a0 in main (argc=1, argv=0x7fff8839b478) at rowdy.c:10 (gdb)continueContinuing.
We used ps to get the PID of the process we want to debug (27318) so at the (gdb) prompt, we enter attach 27318 to attach to the process. When this happens, the process halts but doesn't exit. We can enter where to see where it halted and as expected, it was within the sleep() system call. Enter continue to resume the program. After a few minutes (when the sleep() function returns) the program will then crash and we can debug it as above.
(gdb)continueContinuing. Program received signal SIGSEGV, Segmentation fault. 0x00000038b327b451 in memcpy () from /lib64/libc.so.6 (gdb)where#0 0x00000038b327b451 in memcpy () from /lib64/libc.so.6 #1 0x00000038b32cc355 in gethostname () from /lib64/libc.so.6 #2 0x00000000004005f5 in gethost ( name=0xffffffffffffffff
, len=80) at rowdy.c:23 #3 0x00000000004005b8 in main (argc=1, argv=0x7fff8839b478) at rowdy.c:13 (gdb) detach LND: Sending signal 11 to process 27318 Detaching from program: /home/bobby/howdy/rowdy, process 27318 (gdb) quit [bobby@n083 ~]$ ps -u bobby PID TTY TIME CMD 27321 ? 00:00:00 sshd 27322 pts/0 00:00:00 bash 27429 pts/0 00:00:00 ps [bobby@n083 ~]$ exit Connection to n083 closed. [bobby@n130 howdy]$
We could have used gdb to kill the process but instead we used detach to have the program continue normally. In this case means the program just quits because of the segmentation fault but this allows the batch system to remove the job cleanly.
TotalView
Coming "real soon now"...
Transferring Files
Coming "real soon now"...